from pyCRLD.Agents.ValueSARSA import valSARSA
from pyCRLD.Agents.ValueBase import multiagent_epsilongreedy_strategy
from pyCRLD.Environments.SocialDilemma import SocialDilemma
import numpy as np
import matplotlib.pyplot as pltValue SARSA
CRLD SARSA agents in value space
The value-based SARSA dynamics have been developed and used in the paper, Intrinsic fluctuations of reinforcement learning promote cooperation by Barfuss W, Meylahn J in Sci Rep 13, 1309 (2023).
Example
First, we import the necessary libraries.
Next, we define an epsilon-greedy strategy function. This strategy function selects the best action with probability 1-epsilon and a random action with probability epsilon.
epsgreedy = multiagent_epsilongreedy_strategy(epsilon_greedys=[0.01, 0.01])We define the environment to be a simple stag-hunt game.
env = SocialDilemma(R=1.0, T=0.75, S=-0.15, P=0.0)We use both, the strategy function and the envrionment to create the value-based SARSA multi-agent environment objecte mae
mae = valSARSA(env, discount_factors=0.5, learning_rates=0.1, strategy_function=epsgreedy)We illustrate the value-based SARSA agents by sampling from 50 random initial values and plot the resulting learning times series in value space.
for _ in range(50):
Qinit = mae.random_values()
Qtisa, fpr = mae.trajectory(Qinit, Tmax=1000, tolerance=10e-9)
# plot time series
plt.plot(Qtisa[:, 0, 0, 0]- Qtisa[:, 0, 0, 1],
Qtisa[:, 1, 0, 0]- Qtisa[:, 1, 0, 1],
'.-', alpha=0.1, color='blue')
# plot last point
plt.plot(Qtisa[-1, 0, 0, 0]- Qtisa[-1, 0, 0, 1],
Qtisa[-1, 1, 0, 0]- Qtisa[-1, 1, 0, 1],
'.', color='red')
# plot quadrants
plt.plot([0, 0], [-2, 2], '-', color='gray', lw=0.5)
plt.plot([-2, 2], [0, 0], '-', color='gray', lw=0.5)
plt.xlim(-1.2, 1.2); plt.ylim(-1.2, 1.2)
plt.xlabel(r'action-value difference $Q(coop.) - Q(defect)$ of agent 1');
plt.ylabel(r'$Q(coop.) - Q(defect)$ of agent 2');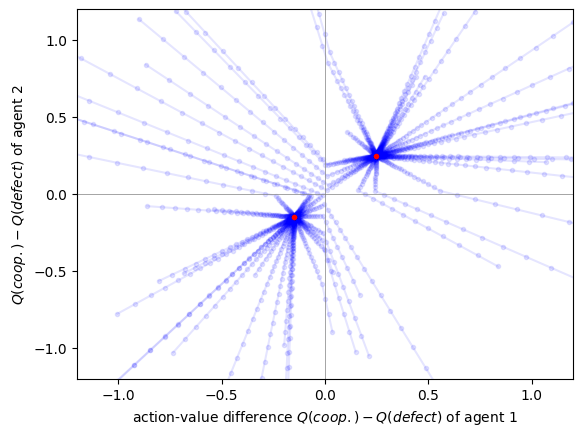
Implementation
valSARSA
valSARSA (env, learning_rates:Union[float,Iterable], discount_factors:Union[float,Iterable], strategy_function, choice_intensities:Union[float,Iterable]=1.0, use_prefactor=False, opteinsum=True, **kwargs)
Class for CRLD-SARSA agents in value space.
| Type | Default | Details | |
|---|---|---|---|
| env | An environment object | ||
| learning_rates | Union | agents’ learning rates | |
| discount_factors | Union | agents’ discount factors | |
| strategy_function | the strategy function object | ||
| choice_intensities | Union | 1.0 | agents’ choice intensities |
| use_prefactor | bool | False | use the 1-DiscountFactor prefactor |
| opteinsum | bool | True | optimize einsum functions |
| kwargs |
The temporal difference reward-prediction error is calculated as follows:
RPEisa
RPEisa (Qisa, norm=False)
Compute temporal-difference reward-prediction error for value SARSA dynamics, given joint state-action values Qisa.
| Type | Default | Details | |
|---|---|---|---|
| Qisa | Joint strategy | ||
| norm | bool | False | normalize error around actions? |
| Returns | ndarray | reward-prediction error |
valRisa
valRisa (Qisa)
Average reward Risa, given joint state-action values Qisa
| Details | |
|---|---|
| Qisa | Joint state-action values |
valNextQisa
valNextQisa (Qisa)
Compute strategy-average next state-action value for agent i, current state s and action a, given joint state-action values Qisa.